
Hadoop experts are going to share detailed information about Hadoop Distribution File System (HDFS). It’s a kind of distributed file system that is intended to stick to the advantages of a conventional distributed file system (DFS) and Google File system or GFS. The big data Hadoop development framework has its own file system, which is called Hadoop Distributed File System (HDFS). It’s a self-healing system designed and developed in Java that has ability to handle and store big data (petabytes or terabytes), regardless of format and schema, offering throughput, high scalability, and reliability while running on huge commodity machine clusters.
HDFS is intended to locate most complications and issues related to traditional file distributed system. Major characteristics of HDFS are- massive data storage, high throughput, single writer/ multiple readers, fault tolerance, commodity machine usage, scalable and file management system, and more.
[Read More: Ultrasonic Cleaners – Great for Removing Buffing Compounds]
Important terminologies used for HDFS
To understand the functionality of HDFS, you must acquire complete knowledge about key terminologies used by Hadoop professionals-
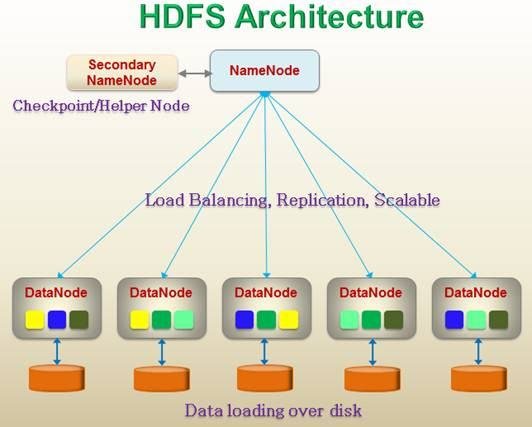
DataNode
DataNode is affordable commodity machine that is used to store large amount of data. It is also named as the workhorse of the file system, which executes all commands driven by NameNode, say for instance- physically deletion, creation, and replication of a block. It also performs low level operations for I/O requests served for the HDFS client and enables pipelining of data and is used for forwarding data to another data node that is present inside the same cluster.
NameNode
It stores and handles metadata information of the file system, such as size, location, hierarchy, permission, etc. NameNode is efficient reliable machine that has a lot o RAM for easy and quick access and to support persistence.
It manages the file system with the transactional log assistance, i.e. it edits the log. NameNode receives regular block reports and a heartbeat from all data nodes present inside the cluster to operate the HDFS cluster health and assure proper functioning of the system.
[Read More: Adopting Economical Software Technology for Managing Customer Database]
Blocks
These are the smallest writable units present on the file system or disk. The blocks are useful for storing larger files- petabyte or zetabyte on HDFS. Its default size (64 MB) supports storing data of zeta bytes or petabytes over large commodity machine in a cluster and offering high throughput for accessing stored data.
Secondary NameNode
Sometimes Hadoop developers also name it as the CheckPointNode or HelperNode. This is a distinct and highly reliable machine that has lot of CPU power and RAM. NameNode edits the Log/Transaction log and merges the NameNode FSImage file with Edits log and develop a new FSImage file.
You now know the terminologies of HDFS and the architecture design. HDFS is extremely reliable and available data storage that is advanced than traditional distributed file system. We hope you like this article and share your valuable comments in below section.



The article is really good with some fantastic points.